#1. Describing Data
Measures of central tendency – Đo lường khuynh hướng của giá trị trung tâm
1. Arithmetic Mean – Trung bình cộng toán học
=AVERAGE(number1, [number2], ...)AVERAGE: tổng các giá trị chia cho số các số.
Có thể sử dụng cách tính tương đương: =SUM(A2:A11)/COUNT(A2:A11)

2. Trimmed Mean – Giá trị bình quân sau khi đã cắt đi x% các giá trị outliers (các giá trị quá lớn/quá nhỏ)
=TRIMMEAN(array, percent)- array: chuỗi số,
- percent: loại đi bao nhiêu phần outliers trong chuỗi số
Trong ví dụ bên dưới, TRIMMEAN loại đi 10% outliers, 10% các giá trị lớn nhất, 10% các giá trị bé nhất. Tập dữ liệu có 10 số, 10% các giá trị lớn nhất là số 96000, và 10% các giá trị bé nhất là số 9000. Sau đó tính bình quân của 8 số còn lại.

Ngoài ra, còn có thể sử dụng cách:
– Bước 1: sử dụng Conditional Formatting để tìm các giá trị thuộc Top 10% và Bottom 10% của chuỗi,
– Bước 2: loại outliers trong công thức tính trung bình cộng SUM/COUNT
3. Winsorized Mean – Giá trị bình quân sau khi đã thay thế số nằm ngoài phân vị x thành giá trị thuộc phân vị x
Excel hiện chưa cung cấp hàm tính winsorized mean, nên chúng ta lần lượt thực hiện các bước sau để tìm ra winsorized mean.
Bước 1: Tính ra phân vị thứ k và 1-k (nhưng cũng không nhất thiết phải là 1-k) trong tập dữ liệu bằng hàm PERCENTILE.EXC (lưu ý, hàm này khác với PERCENTILE.INC)
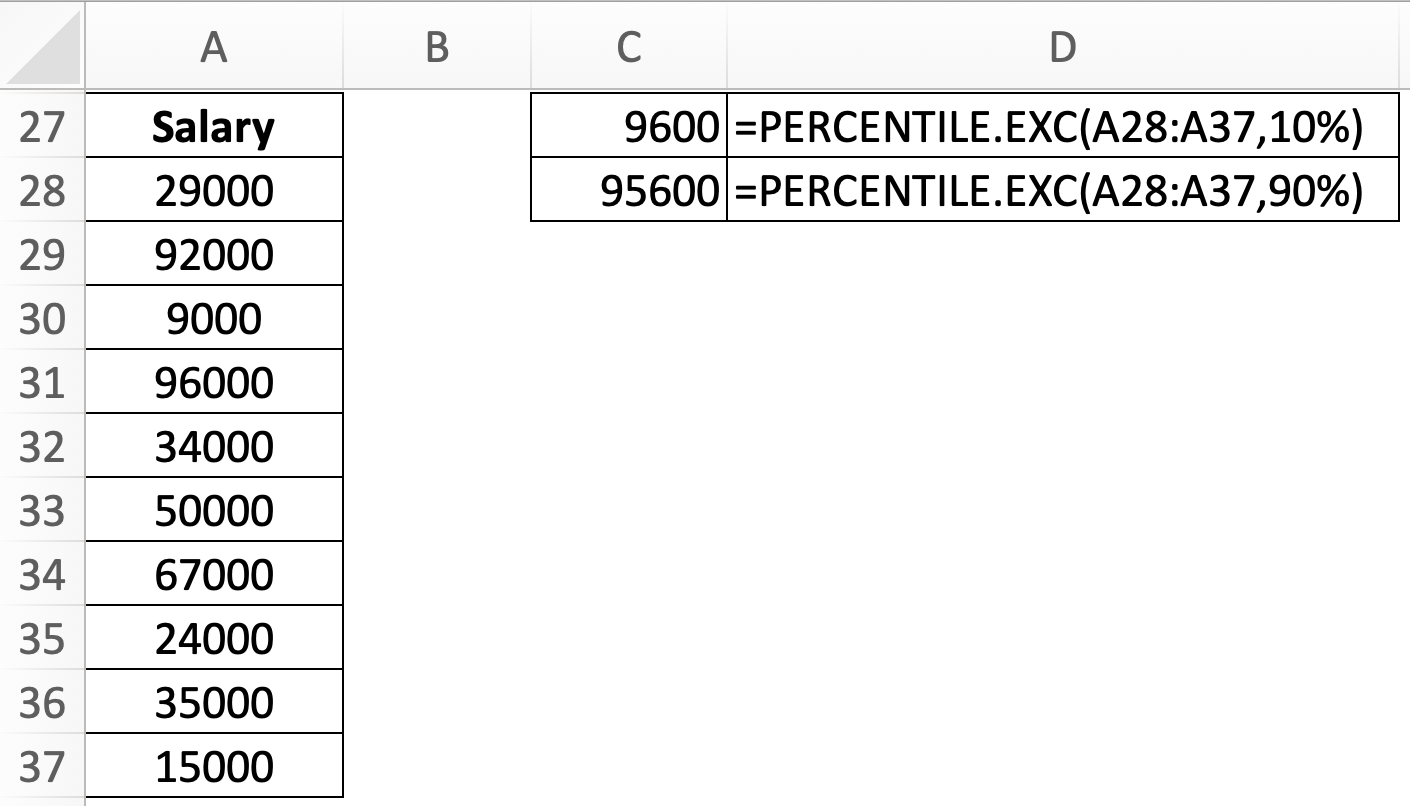
Bước 2: Sau khi tìm được phân vị thứ k và 1-k ở hai đầu dữ liệu, chúng ta sẽ thay thế các giá trị nằm ngoài hai mốc này thành số vừa tìm được ở phân vị thứ k và 1-k.

Bước 3: Winsorized mean được tính từ các giá trị sau khi đã được winsorized

4. Weighted mean – Bình quân gia quyền (tổng của các tích giá trị x tỷ trọng)
Excel hiện chưa cung cấp hàm tính weighted mean, nên chúng ta lần lượt thực hiện các bước sau để tìm ra weighted mean.
Bước 1: Tính tỷ trọng của từng giá trị trong tập dữ liệu
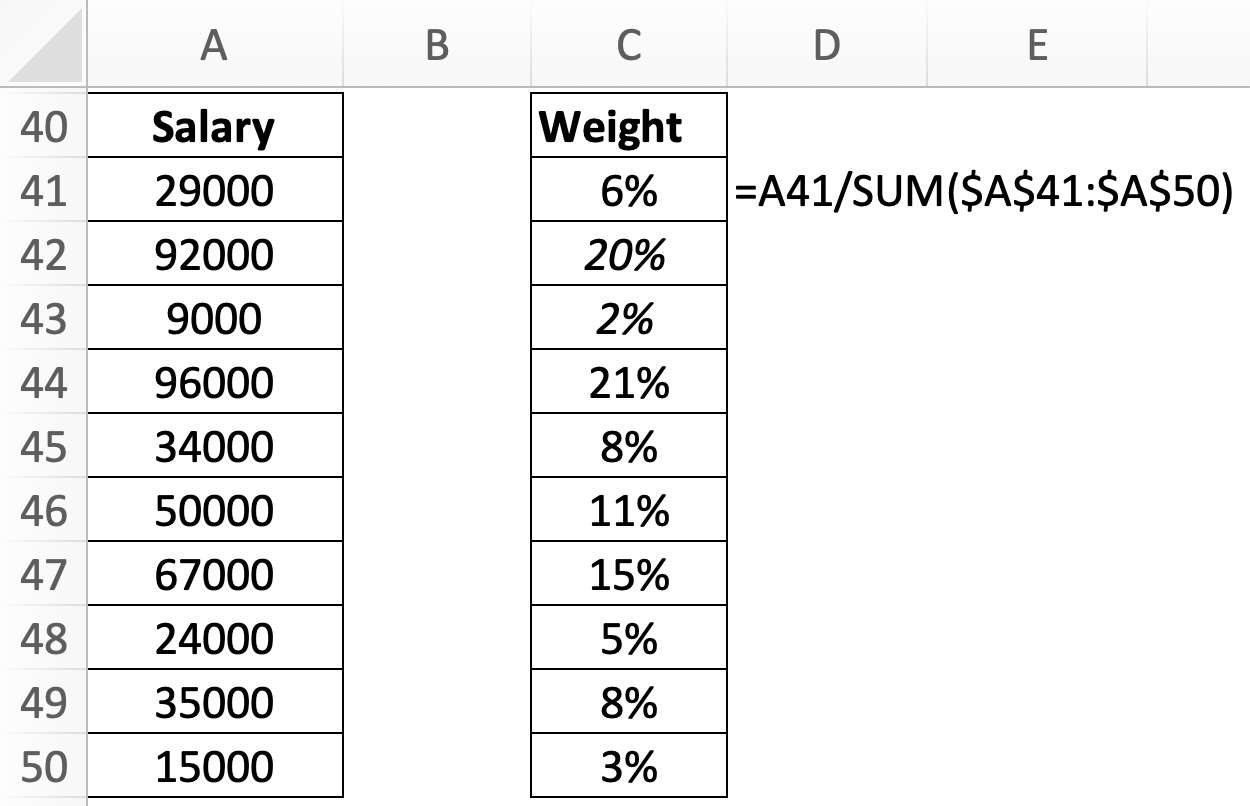
Bước 2: Tính tổng của các cặp tích salary x weight bằng hàm SUMPRODUCT

Cách tính bình quân này có thể áp dụng để tính bình quân lợi suất của doanh mục đầu tư dựa trên tỷ trọng vốn và lợi suất mang lại của mỗi khoản đầu tư trong danh mục
5. Geometric mean – Trung bình nhân (căn bậc x của tích x số)
=GEOMEAN(number1, [number2], ...)GEOMEAN lấy căn bậc n của n số trong chuỗi

6. Harmonic mean – Trung bình điều hoà (số các số chia cho tổng các đối ứng của các số đó)
=HARMEAN(number1, [number2], ...)
Measures of Location and Dispersion – Đo lường phân bổ và phân tán của dữ liệu
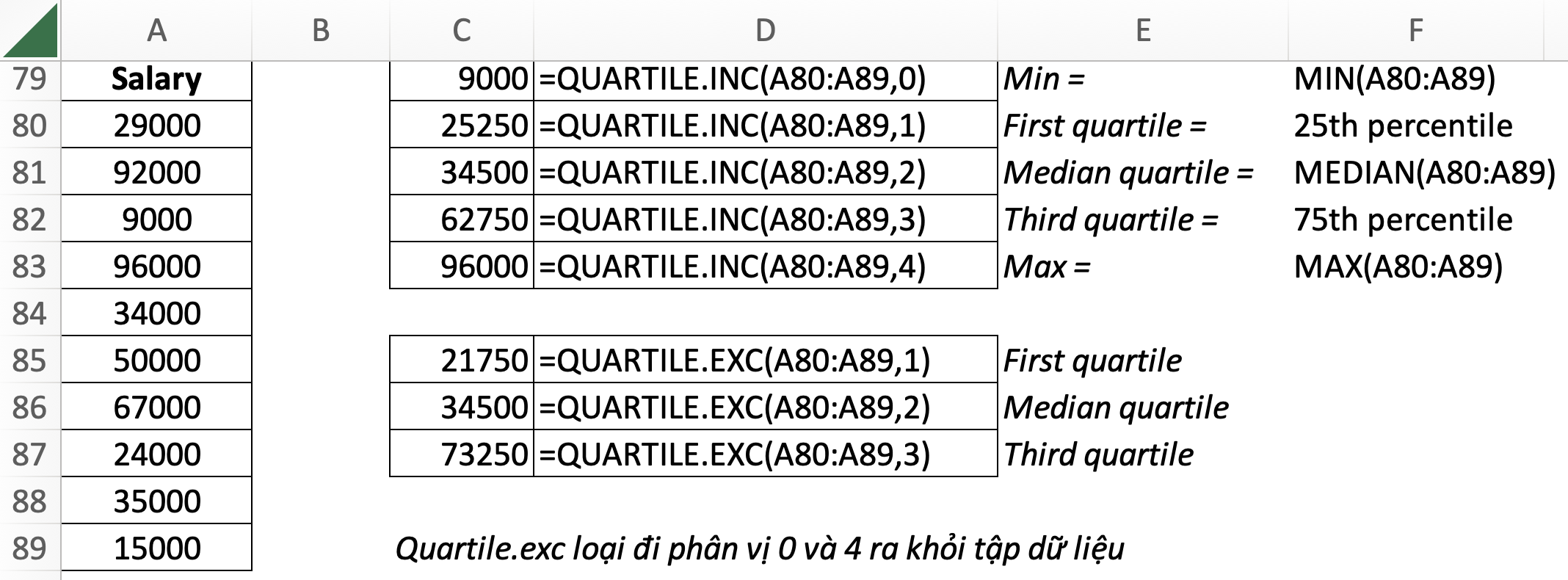
7. Quartile – Tứ phân vị (chia tập dữ liệu thành 4 phần)
=QUARTILE.INC(array,quart)- array: chuỗi số,
- quart: phân vị muốn trả về
8. Percentile – Bách phân vị (chia dữ liệu thành 100 điểm)
=PERCENTILE.INC(array,k)k: bách phân vị thứ k,
k = 0.1: bách phân vị thứ mười ~ thập phân vị thứ nhất (first decile),
k = 0.2: bách phân vị thứ hai mươi ~ thập phân vị thứ hai (second decile) ~ ngũ phân vị thứ nhất (first quintile)
…
k = 0.9: bách phân vị thứ chín mươi ~ thập phân vị thứ chín (ninth decile)

9. Standard Deviation – Độ lệch chuẩn
=STDEV.P(number1,[number2],...)Nếu dữ liệu đại diện cho một mẫu của tổng thể thì sử dụng hàm VAR.S

10. Coefficient of Variation – Hệ số biến thiên
Excel chưa hỗ trợ hàm tìm hệ số biến thiên, nên chúng ta sẽ kết hợp hàm STDEV và AVERAGE để tìm ra CV (coefficient of variation)

“CV cho thấy mức độ biến thiên của dữ liệu trong một mẫu tương quan với giá trị trung bình của tổng thể. Trong tài chính, hệ số biến thiên giúp nhà đầu tư xác định được mức độ dao động hay rủi ro phải chịu để có lợi nhuận kì vọng của khoản đầu tư” – theo vietnambiz.vn
Skewness, Kurtosis and Correlation – Độ xiên, độ nhọn, độ tương quan và hiệp phương sai
11. Skewness – Độ xiên và Kurtosis – Độ nhọn
=SKEW(number1, [number2], ...)=KURT(number1, [number2], ...)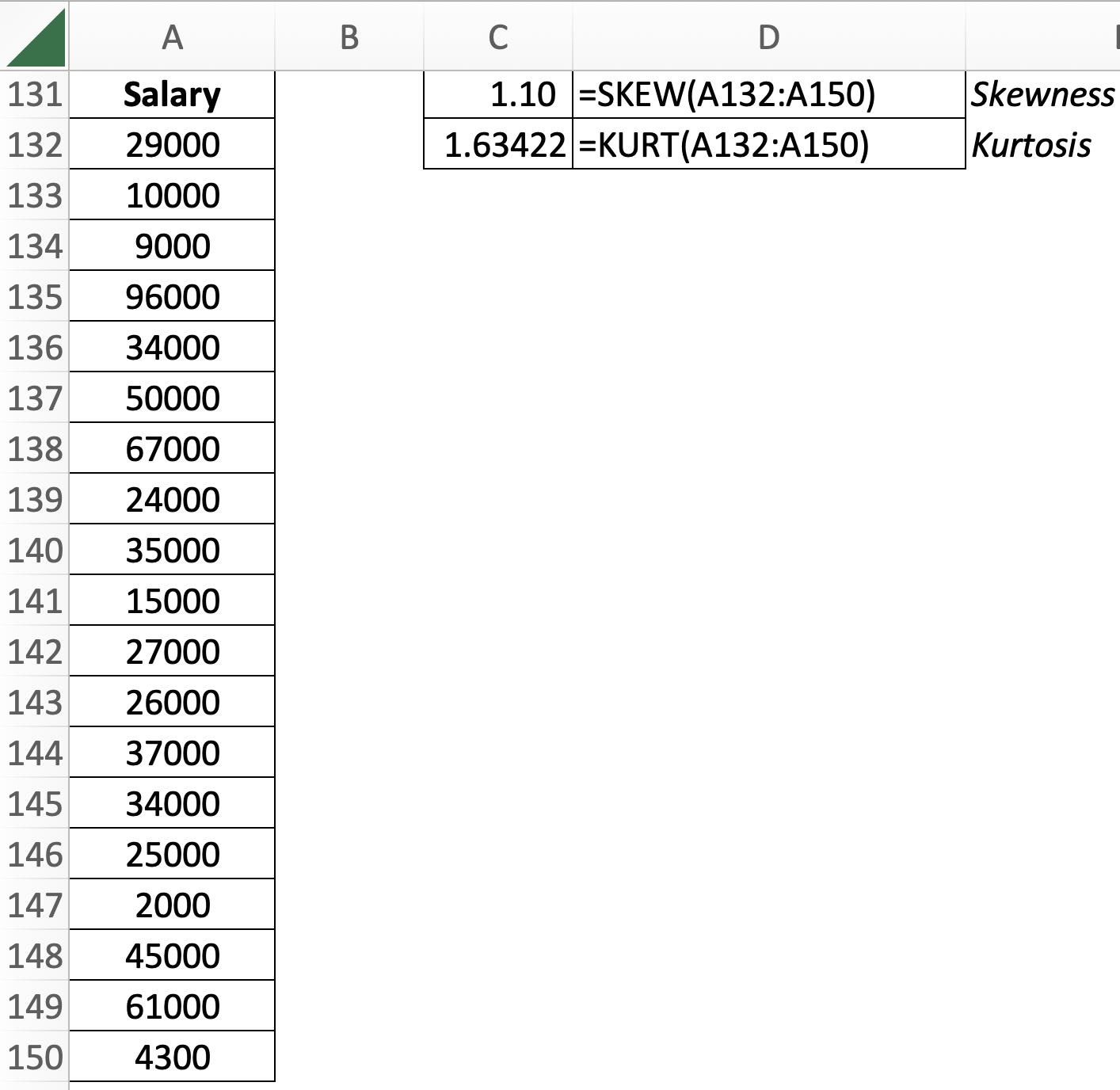
“Giá trị kurtosis: đo độ đỉnh hoặc độ phẳng của phân phối khi so sánh với phân phối chuẩn. Một giá trị dương cho biết phân phối tương đối đạt đỉnh và giá trị âm cho biết phân phối tương đối bằng phẳng. Các phân phối cao hơn hoặc nhọn hơn so với phân phối chuẩn được gọi là leptokurtic, trong khi phân phối phẳng hơn được gọi là platykurtic” – theo phantichspss.com
“Trong khi kurtosis đề cập đến chiều cao của phân phối, skewness được sử dụng để mô tả sự cân bằng của phân phối; nghĩa là, nó không cân đối và bị lệch sang một bên (phải hoặc trái) hay nó có trọng tâm và đối xứng với cùng một hình dạng ở cả hai bên? Nếu một phân phối không cân bằng, nó sẽ bị lệch(skew). Độ lệch dương biểu thị sự phân bố dịch chuyển sang trái, trong khi độ lệch âm phản ánh sự dịch chuyển sang phải” – theo phantichspss.com
12. Covariance – Hiệp phương sai
=COVARIANCE.P(array1,array2)Hiệp phương sai xác định các giá trị trung bình của hai biến di chuyển cùng nhau như thế nào. Nếu lợi nhuận của cổ phiếu A tăng bất cứ khi nào lợi nhuận của cổ phiếu B tăng và hiện tượng tương tự cũng xảy ra khi lợi nhuận của mỗi cổ phiếu giảm, thì các cổ phiếu này được cho là có hiệp phương sai dương. Trong tài chính, hiệp phương sai được tính toán để giúp đa dạng hóa nắm giữ cổ phiếu.

Khi kết quả cho hiệp phương sai dương, nhà phân tích có thể nói rằng sự tăng trưởng của dòng sản phẩm mới của công ty có mối quan hệ tích cực với tăng trưởng GDP hàng quí.
13. Correlation – Độ tương quan
=CORREL(array1, array2)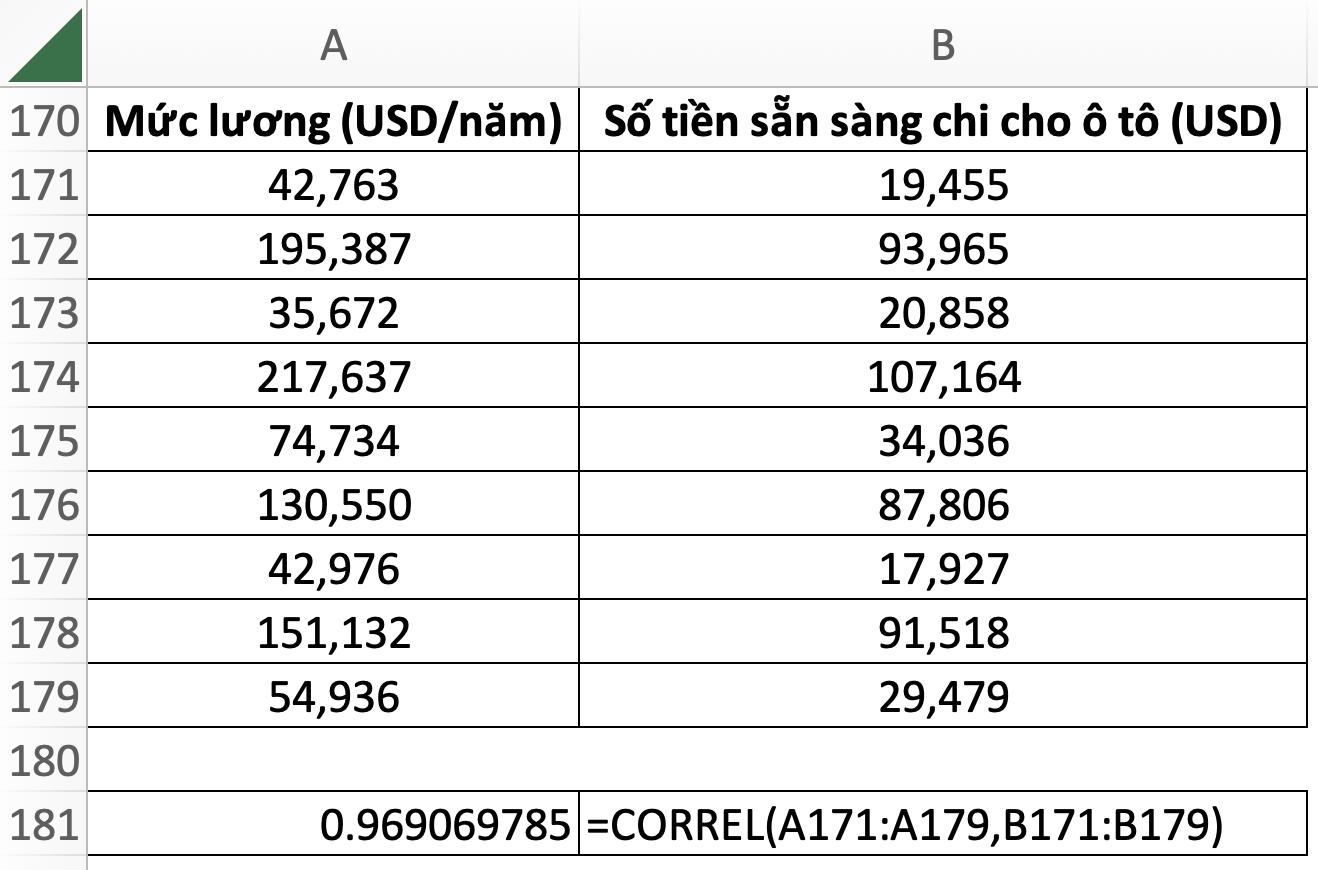
Hệ số tương quan là chỉ số thống kê đo lường mức độ mạnh yếu của mối quan hệ giữa hai biến số. Trong đó:
Hệ số tương quan có giá trị từ -1.0 đến 1.0. Kết quả được tính ra lớn hơn 1.0 hoặc nhỏ hơn -1 có nghĩa là có lỗi trong phép đo tương quan.
– Hệ số tương quan có giá trị âm cho thấy hai biến có mối quan hệ nghịch biến hoặc tương quan âm (nghịch biến tuyệt đối khi giá trị bằng -1)
– Hệ số tương quan có giá trị dương cho thấy mối quan hệ đồng biến hoặc tương quan dương (đồng biến tuyệt đối khi giá trị bằng 1)
– Tương quan bằng 0 cho hai biến độc lập với nhau.
#2. Profitability – Xác suất
14. PROB – Tính xác suất giá trị xuất hiện trong một phạm vi giới hạn
=PROB(x_range, prob_range, [lower_limit], [upper_limit])- x_range: phạm vi giá trị của x có các xác suất gắn với nó
- prob_range: chuỗi xác suất gắn với các giá trị tương ứng trong x_range
- lower_limit: giới hạn dưới của giá trị muốn có xác suất
- upper_limit: giới hạn trên của giá trị muốn có xác suất

15. Factorial – Giai thừa
=FACT(number)Ví dụ:
3! = 3x2x1 = 6
4! = 4x3x2x1 = 24
5! = 5x4x3x2x1 = 120
6! = 6x5x4x3x2x1 = 720

Principles of Counting – Các nguyên lý đếm dữ liệu
16. Combination Formula (1) – Tổ hợp (các cách chọn ra n phần tử từ một tập hợp các số mà không được đảo thứ tự giữa chúng)
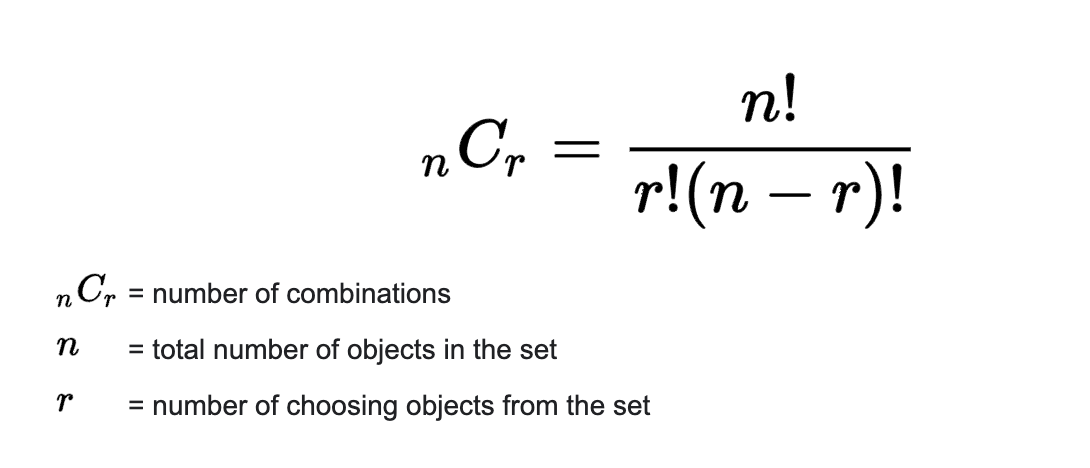
=COMBIN(number, number_chosen)Có bao nhiêu cách chọn ra 2 số từ 5 số mà không được đảo thứ tự của chúng?
Cách 1: 1-2
Cách 2: 2-3
Cách 3: 3-4
Cách 4: 4-5
Cách 5: 1-3
Cách 6: 1-4
Cách 7: 1-5
Cách 8: 2-4
Cách 9: 2-5
Cách 10: 3-5

17. Combination Formula (2) – Tổ hợp (các cách chọn ra n phần tử từ một tập hợp các số và chúng có thể lặp lại)
=COMBINA(number, number_chosen)Có bao nhiêu cách chọn ra 2 số từ 5 số mà không được đảo thứ tự của chúng như các số có thể lặp lại?
Ngoài 10 cách giữ nguyên thứ tự như trên, chúng ta còn có 5 cách lặp lại số:
Cách 11: 1-1
Cách 12: 2-2
Cách 13: 3-3
Cách 14: 4-4
Cách 15: 5-5

18. Permutation Formula (1) – Hoán vị (các cách chọn ra n phần tử từ một tập hợp các số và chúng có thể hoán đổi vị trí)
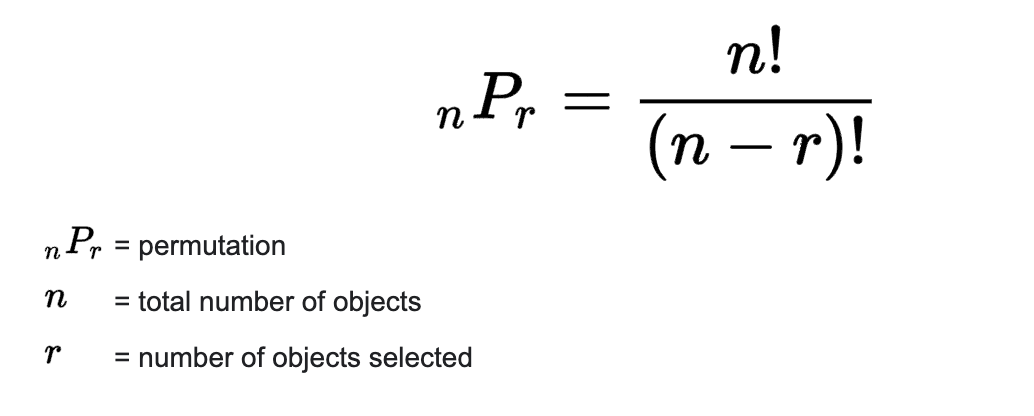
=PERMUT(number, number_chosen)Có bao nhiêu cách chọn ra 2 số từ 5 số mà các số có thể thay đổi vị trí cho nhau?
Cách 1: 1-2 Cách 2: 2-1
Cách 3: 1-3 Cách 4: 3-1
Cách 5: 1-4 Cách 6: 4-1
Cách 7: 1-5 Cách 8: 5-1
Cách 9: 2-3 Cách 10: 3-2
Cách 11: 2-4 Cách 12: 4-2
Cách 13: 2-5 Cách 14: 5-2
Cách 15: 3-4 Cách 16: 4-3
Cách 17: 3-5 Cách 18: 5-3
Cách 19: 4-5. Cách 20: 5-4

19. Permutation Formula (2) – Hoán vị (các cách chọn ra n phần tử từ một tập hợp các số và các số có thể lặp lại)
=PERMUTATIONA(number, number_chosen)Có bao nhiêu cách chọn ra 2 số từ 4 số mà các số có thể thay đổi vị trí cho nhau và các số có thể lặp lại?
Ngoài 20 cách ở ví dụ trên, chúng ta còn có 5 cách:
Cách 21: 1-1
Cách 22: 2-2
Cách 23: 3-3
Cách 24: 4-4
Cách 25: 5-5

#3. Profitability Distributions – Phân bổ xác suất
Normal Distribution – Phân phối chuẩn
20. STANDARDIZE: Chuẩn hoá
=STANDARDIZE(x, mean, standard_dev)- x: giá trị muốn chuẩn hoá,
- mean: trung bình số học của phân phối,
- standard_dev: độ lệch chuẩn của phân phối
STANDARDIZE trả về giá trị chuẩn hóa (z-score) (co giãn dữ liệu) dựa vào mean và standard_dev. Hàm này thường được dùng để chuẩn hoá và so sánh các giá trị không cùng đơn vị đo.
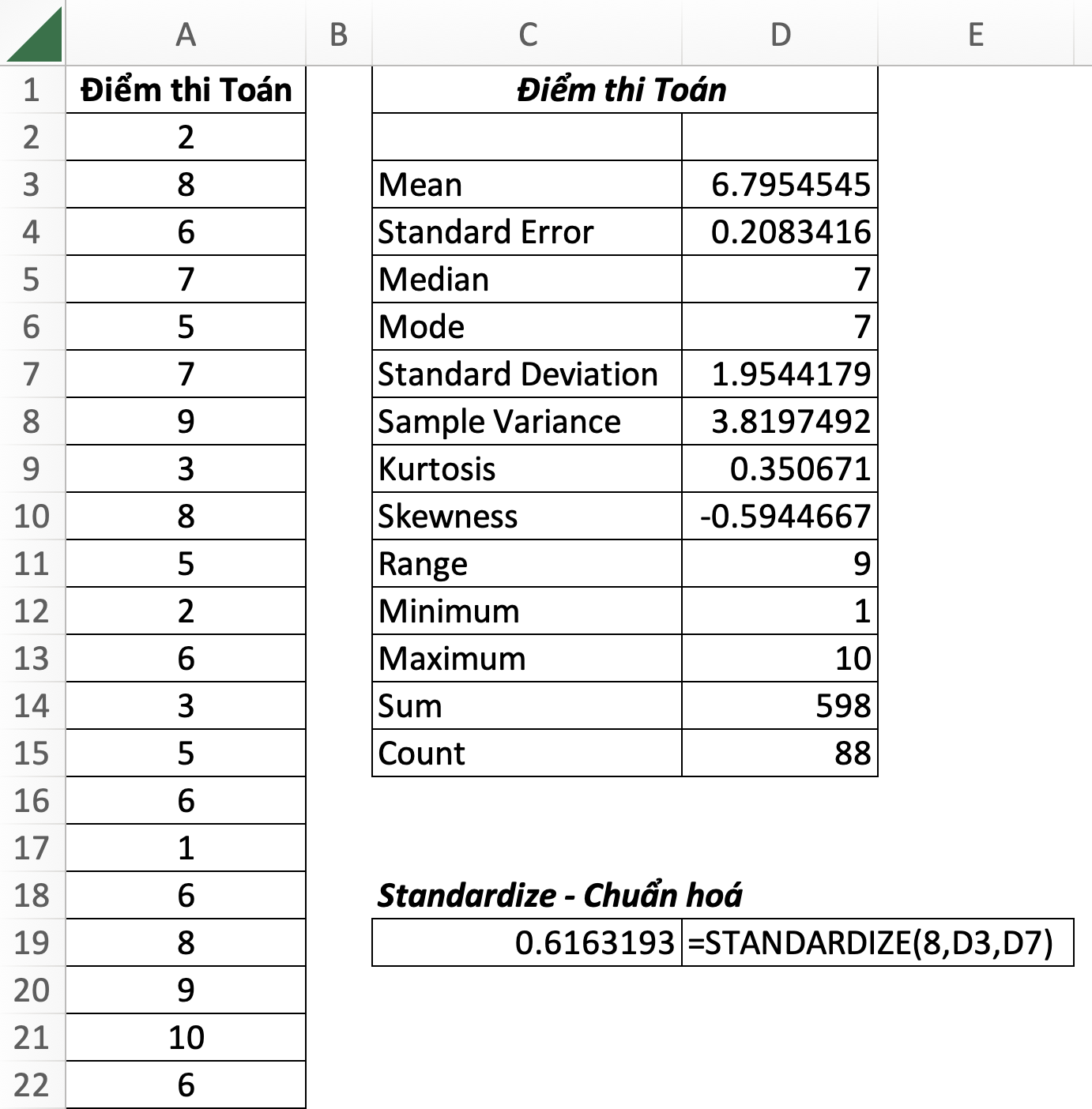
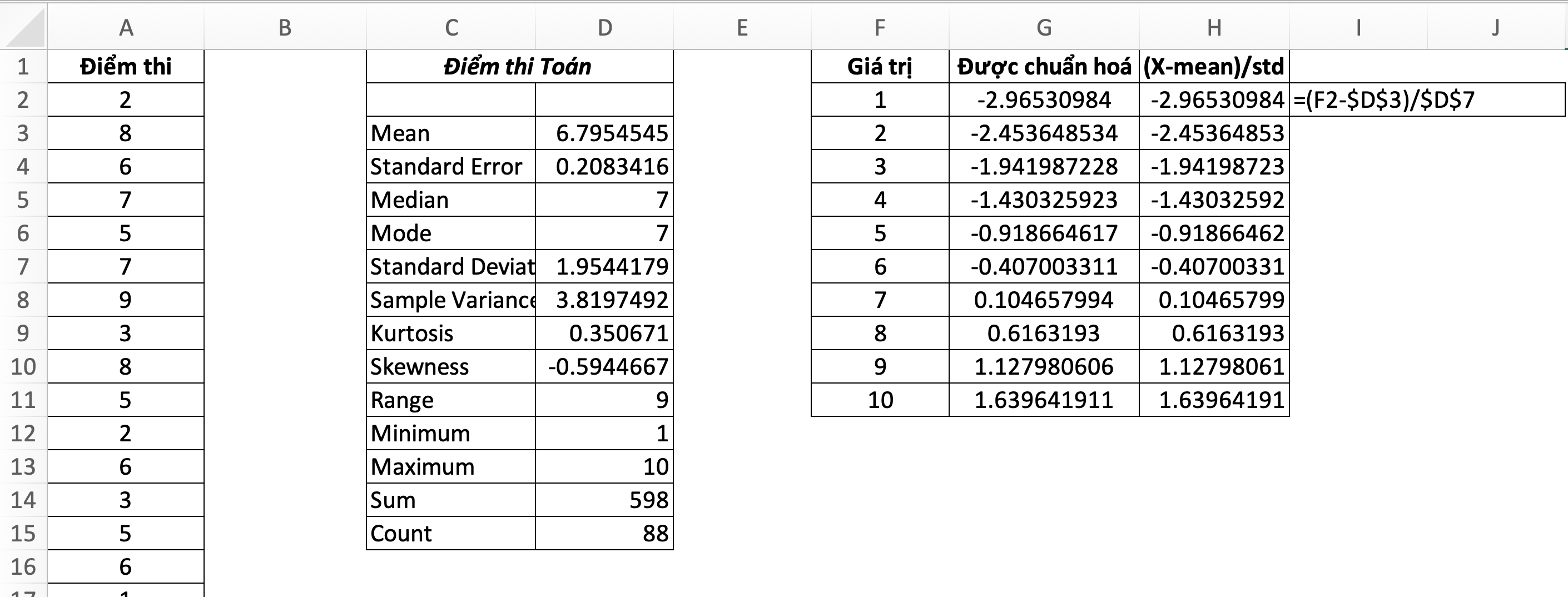
Các giá trị có z-score < 0 là những số < mean (6.79). Ngược lại, các giá trị có z-score > 0 là những số > mean.
Quá trình chuẩn hoá dữ liệu là một bước xử lý dữ liệu hữu ích, giúp dễ dàng so sánh dữ liệu từ khác tập dữ liệu khác nhau có độ lớn và phân bổ khác nhau.
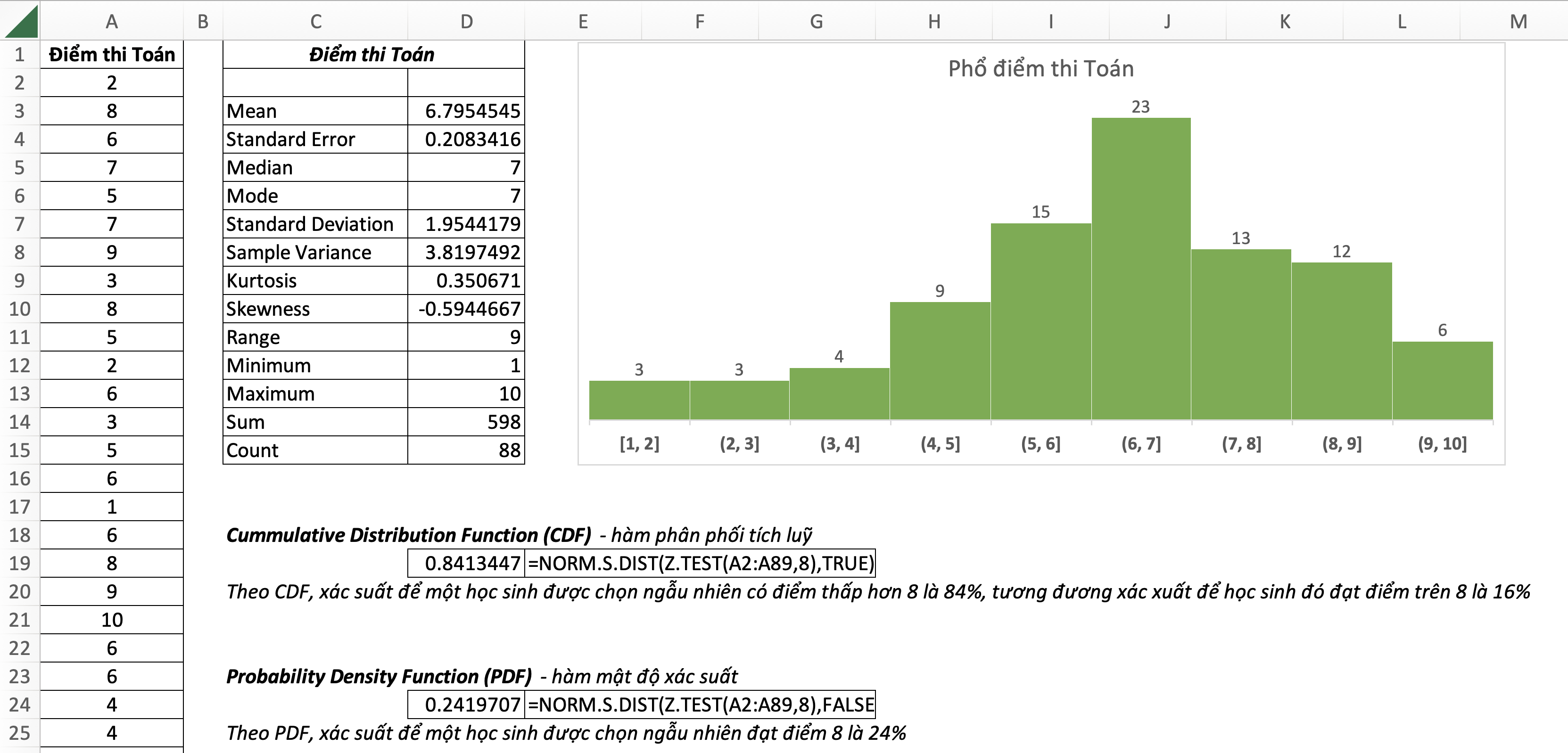
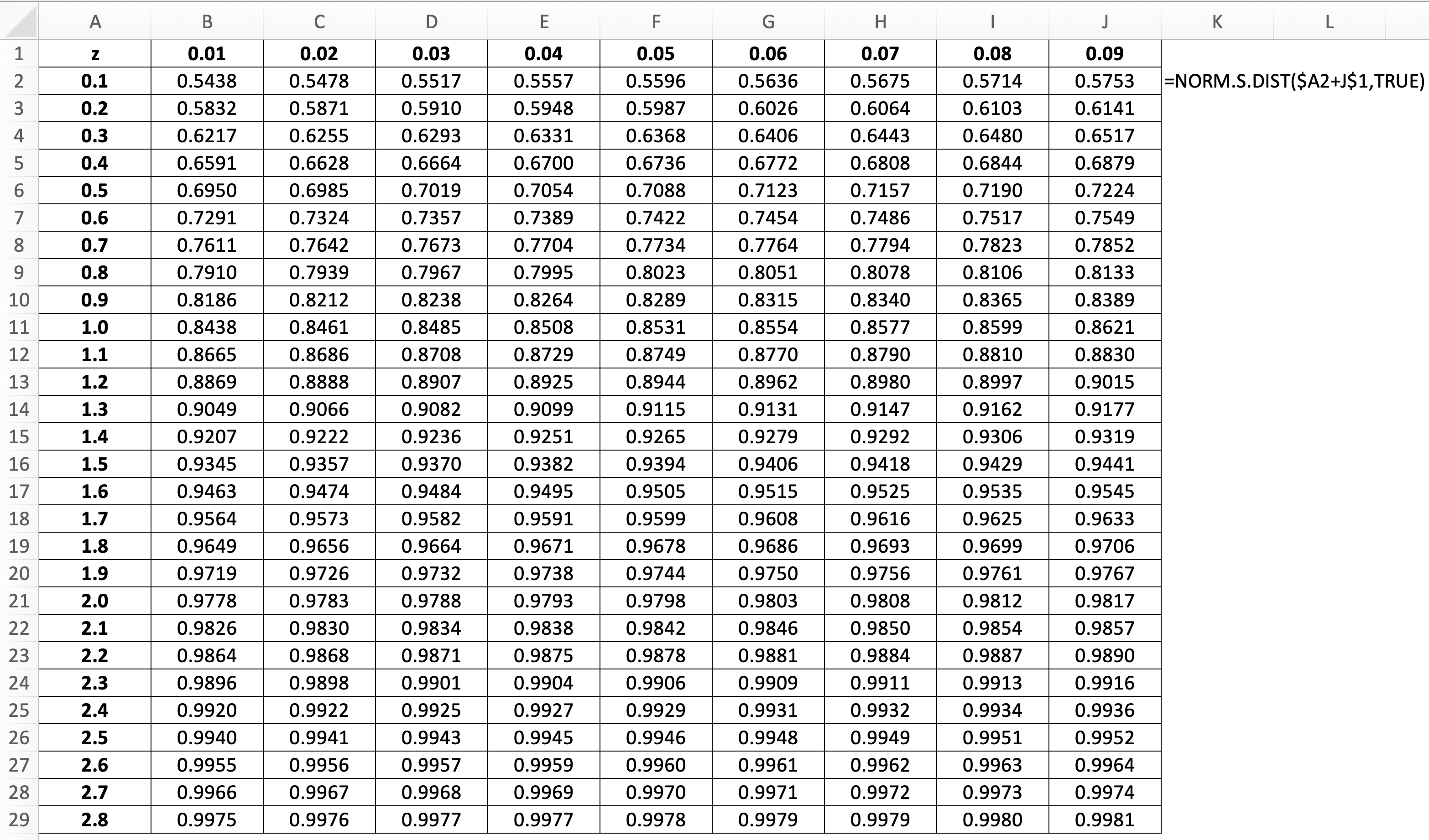
21. NORM.DIST – Normal Distribution: Phân phối chuẩn
=NORM.DIST(x,mean,standard_dev,cumulative)- x: giá trị cần xác định phân phối
- mean: trung bình số học của phân phối
- standard_dev: độ lệch chuẩn của phân phối
- cumulative: TRUE (hoặc 1): hàm phân phối tích luỹ; FALSE (hoặc 0): hàm mật độ xác suất
22. NORM.S.DIST – Normal Standardized Distribution: Phân phối chuẩn chuẩn hoá
=NORM.S.DIST(z,cumulative)NORM.S.DIST sử dụng phân phối chuẩn chuẩn hoá – là một trường hợp đặc biệt của phân phối chuẩn – tại đó mean = 0 và standard_dev = 1
Trong khi NORM.DIST sử dụng mean và standard_dev của tập dữ liệu.
- z: số lượng độ lệch chuẩn kể từ giá trị mean. Ví dụ: z = -1.5<0 là một + một nửa độ lệch chuẩn nằm dưới mean; z = 2>0 là 2 độ lệch chuẩn nằm trên mean
- cumulative: TRUE (hoặc 1): hàm phân phối tích luỹ; FALSE (hoặc 0): hàm mật độ xác suất
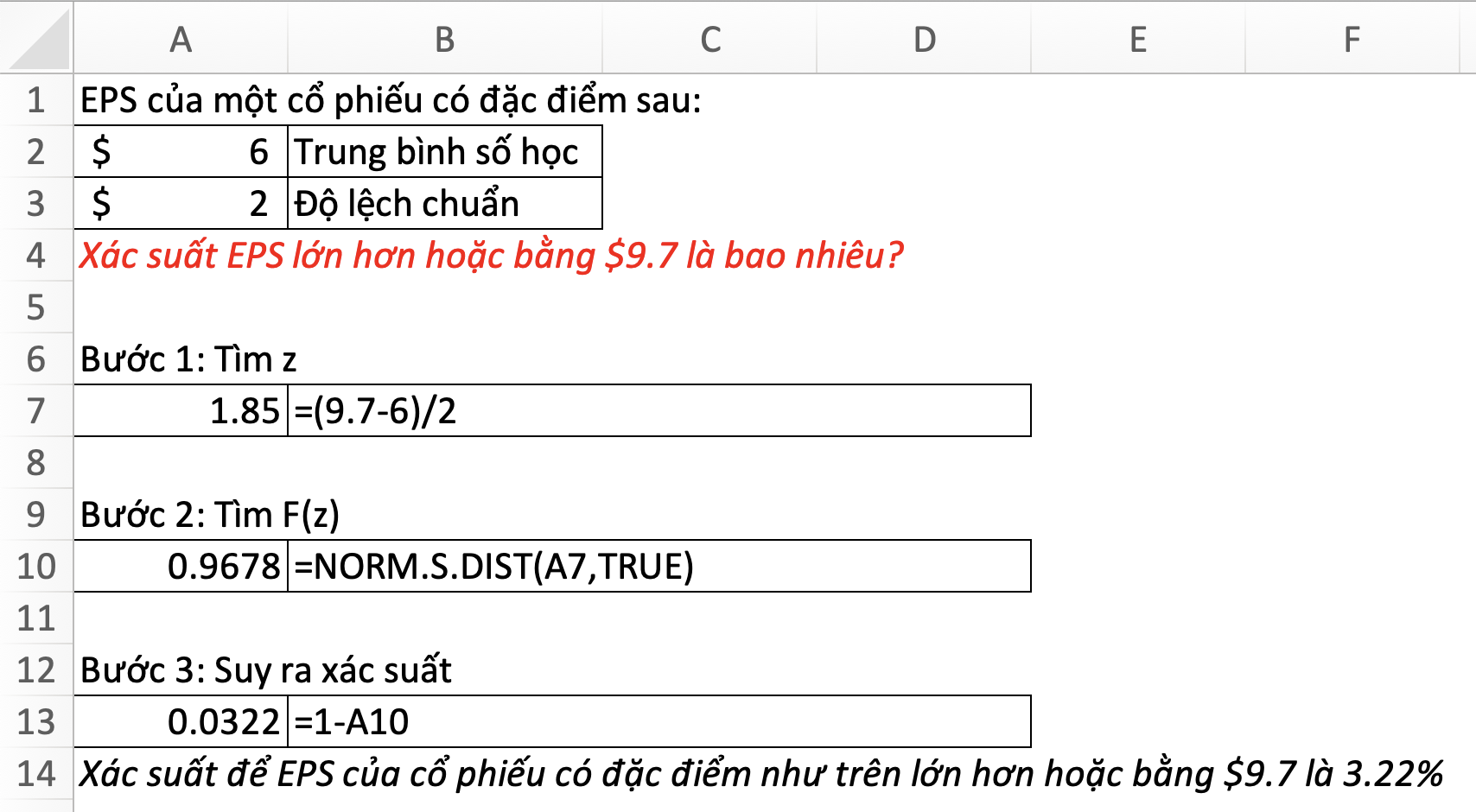
Xem thêm về z-table tại đây. Hoặc tự tạo bảng tra cứu z bằng hàm NORM.S.DIST như hình bên dưới:
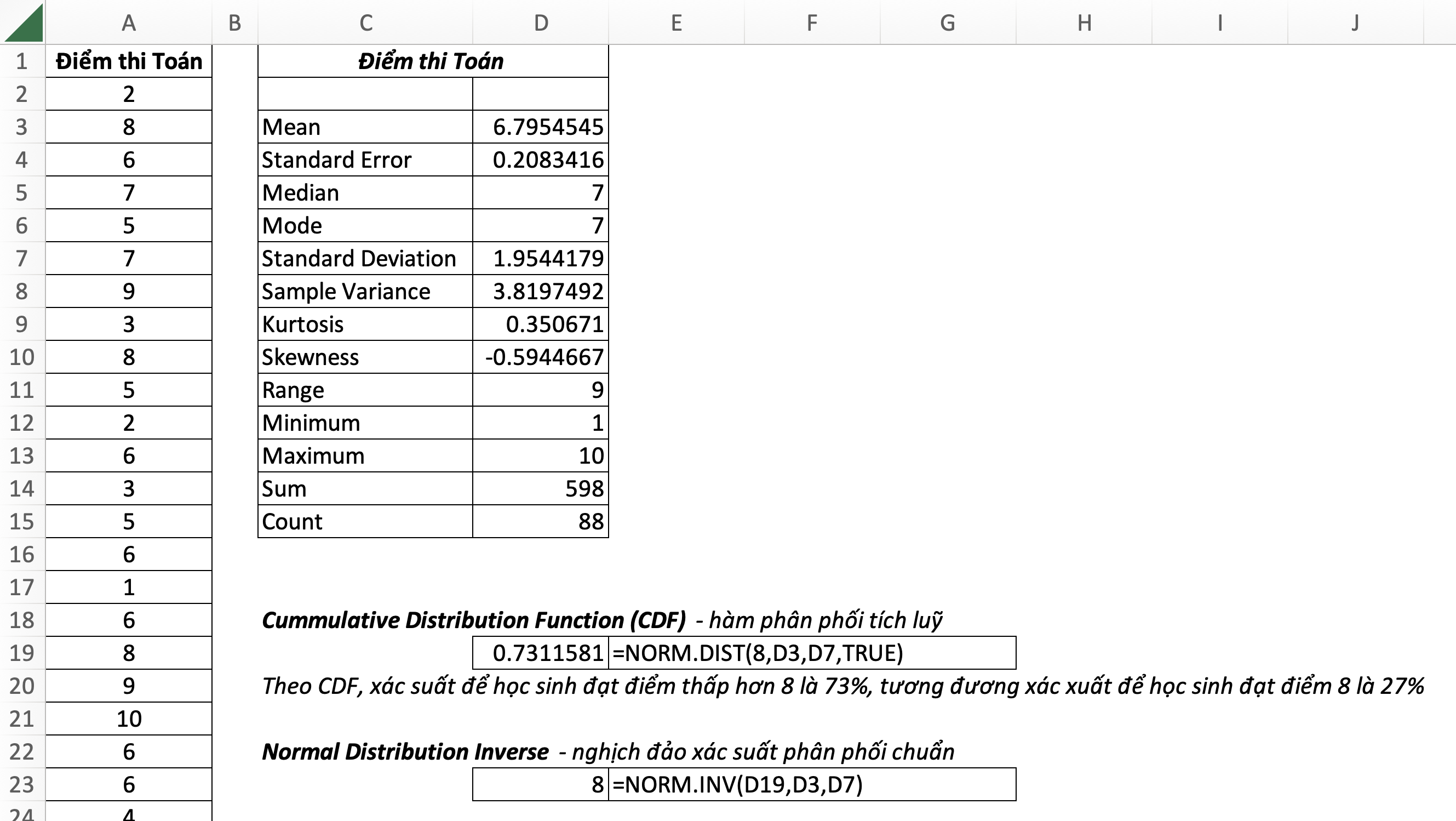
23. NORM.INV – Normal Distribution Inverse
=NORM.INV(probability,mean,standard_dev)- probability: một xác suất tương ứng với phân bố chuẩn
- mean: trung độ số học của phân phối
- standard_dev: độ lệch chuẩn của phân phối
24. NORM.S.INV – Normal Standardized Inverse: Phân phối chuẩn nghịch đảo
=NORM.S.INV(probability)- probability: xác suất tương ứng với phân bố chuẩn
NORM.S.INV trả về giá trị đảo của phân bố lũy tích chuẩn chuẩn hóa

Binomial Distribution: Phân phối nhị thức
25. BINOM.DIST – Binomial Distribution: Phân phối nhị thức
=BINOM.DIST(number_s,trials,probability_s,cumulative)- number_s: số lần thử thành công
- trials: tổng số lần thử độc lập
- probability_s: xác suất số lần thử thành công
- cumulative: TRUE (hoặc 1): hàm phân phối tích luỹ; FALSE (hoặc 0): hàm mật độ xác suất
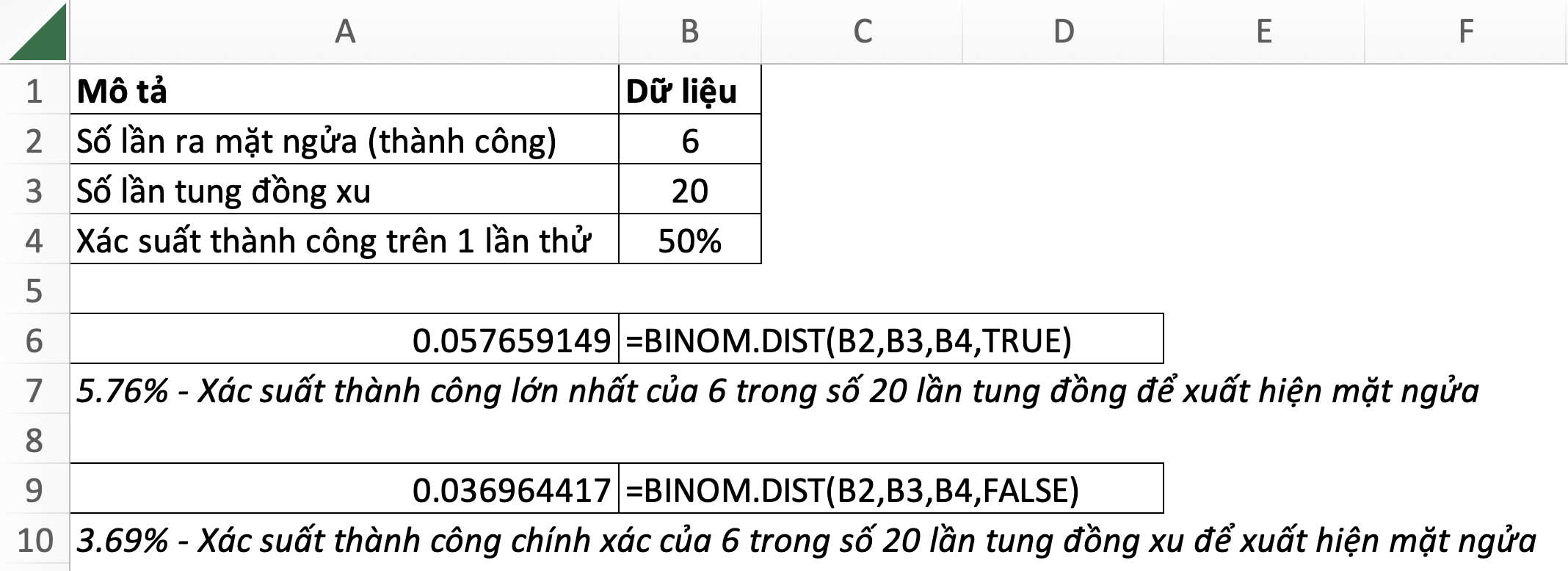
26. BINOM.DIST.RANGE – Binomial Distribution Range: Phân phối nhị thức theo phạm vi
=BINOM.DIST.RANGE(trials,probability_s,number_s,[number_s2])- number_s: số lần thử thành công đợt 1
- number_s2: số lần thử thành công đợt 2 (thường lớn hơn đợt 1), nếu bỏ qua, hàm trả về xác suất bằng bới NORM.DIST(FALSE)
- trials: tổng số lần thử độc lập
- probability_s: xác suất số lần thử thành công
- cumulative: TRUE (hoặc 1): hàm phân phối tích luỹ; FALSE (hoặc 0): hàm mật độ xác suất

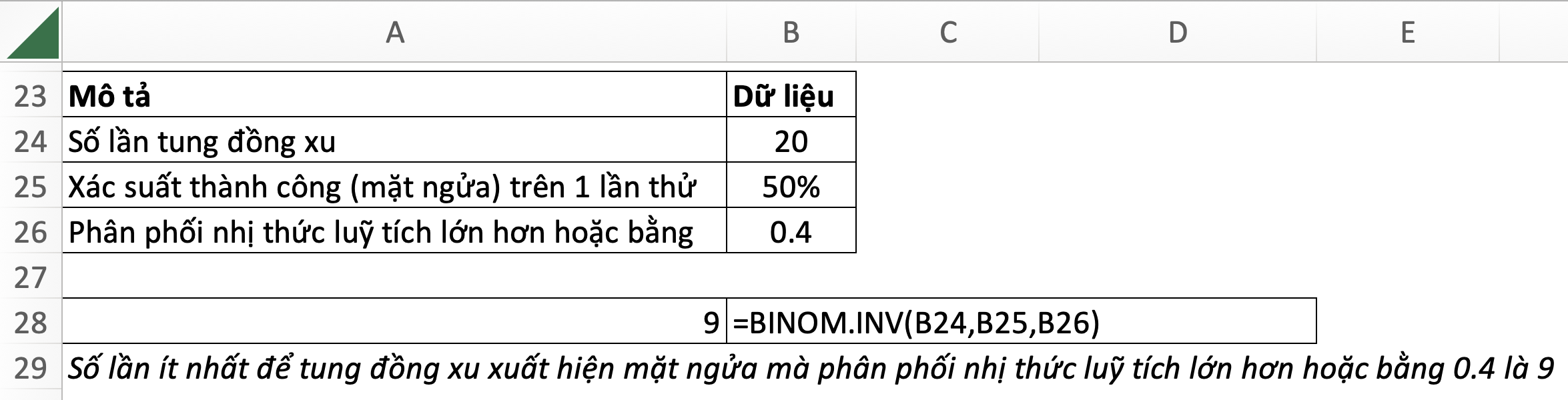
27. BINOM.INV – Binomial Inverse: Phân phối nhị thức nghịch đảo
=BINOM.INV(trials,probability_s,alpha)- trials: tổng số lần thử độc lập
- probability_s: xác suất số lần thử thành công
- alpha: xác suất phân phối nhị phân luỹ tích, nằm giữa 0 và 1
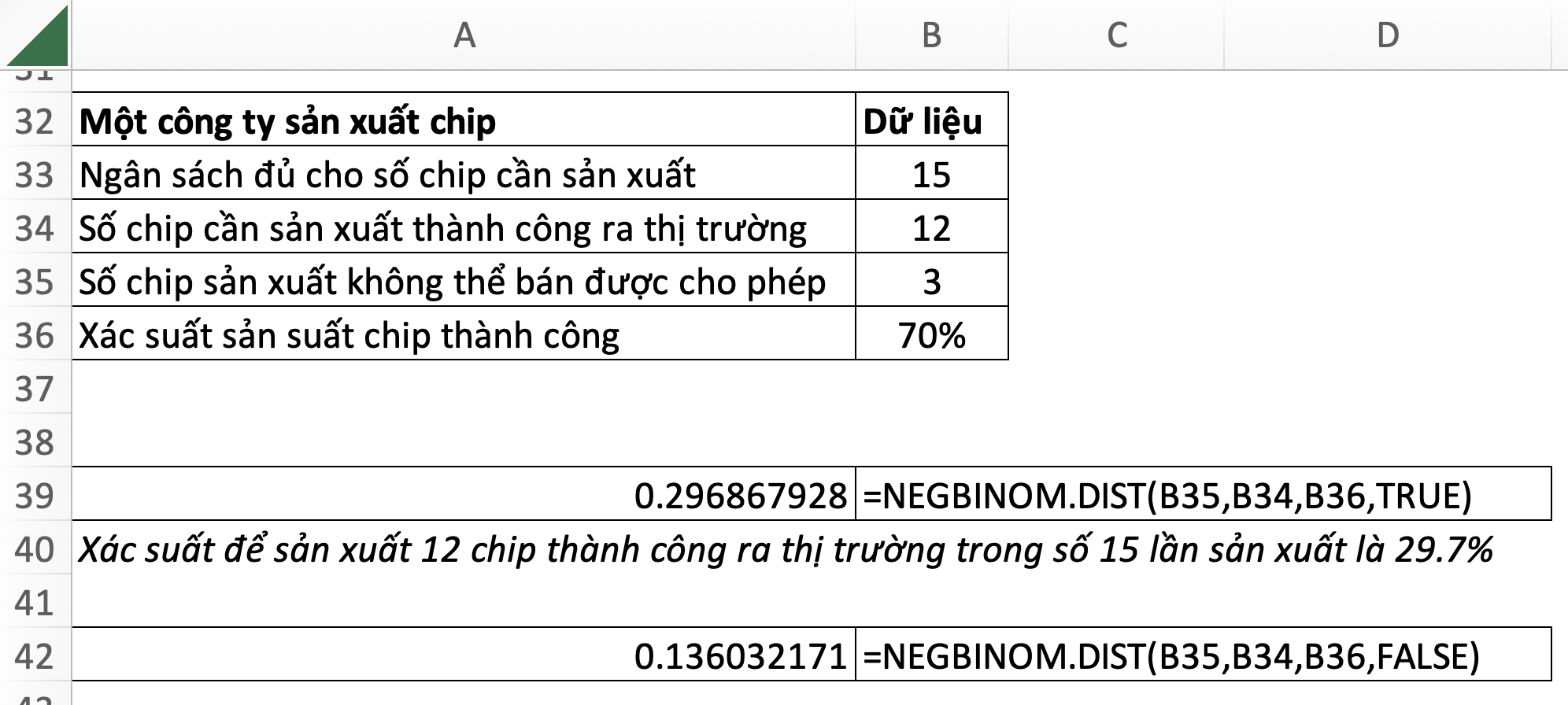
28. NEGBINOM.DIST – Negative Binomial Distribution: Phân phối nhị thức âm
=NEGBINOM.DIST(number_f,number_s,probability_s,cumulative)- number_s: số lần thử thành công đợt 1
- number_f: số lần thử thất bại
- probability_s: xác suất số lần thử thành công
- cumulative: TRUE (hoặc 1): hàm phân phối tích luỹ; FALSE (hoặc 0): hàm mật độ xác suất
Lognormal Distribution: Phân phối log-normal
29. LN/LOG/LOG10 – Logarithm: Logarit
=LN(number) // Natural logarithm - logarit tự nhiên=LOG(number) //logarit=LOG10(number) // Common logarithm - logarit thông thườngLogarit được sử dụng để giải các phương trình có số mũ là biến số

30. EXP – Exponential: Luỹ thừa cơ số e
=EXP(number)EXP lấy luỹ thừa bật “number” với cơ số e, trong đó e = 2.71828182845904
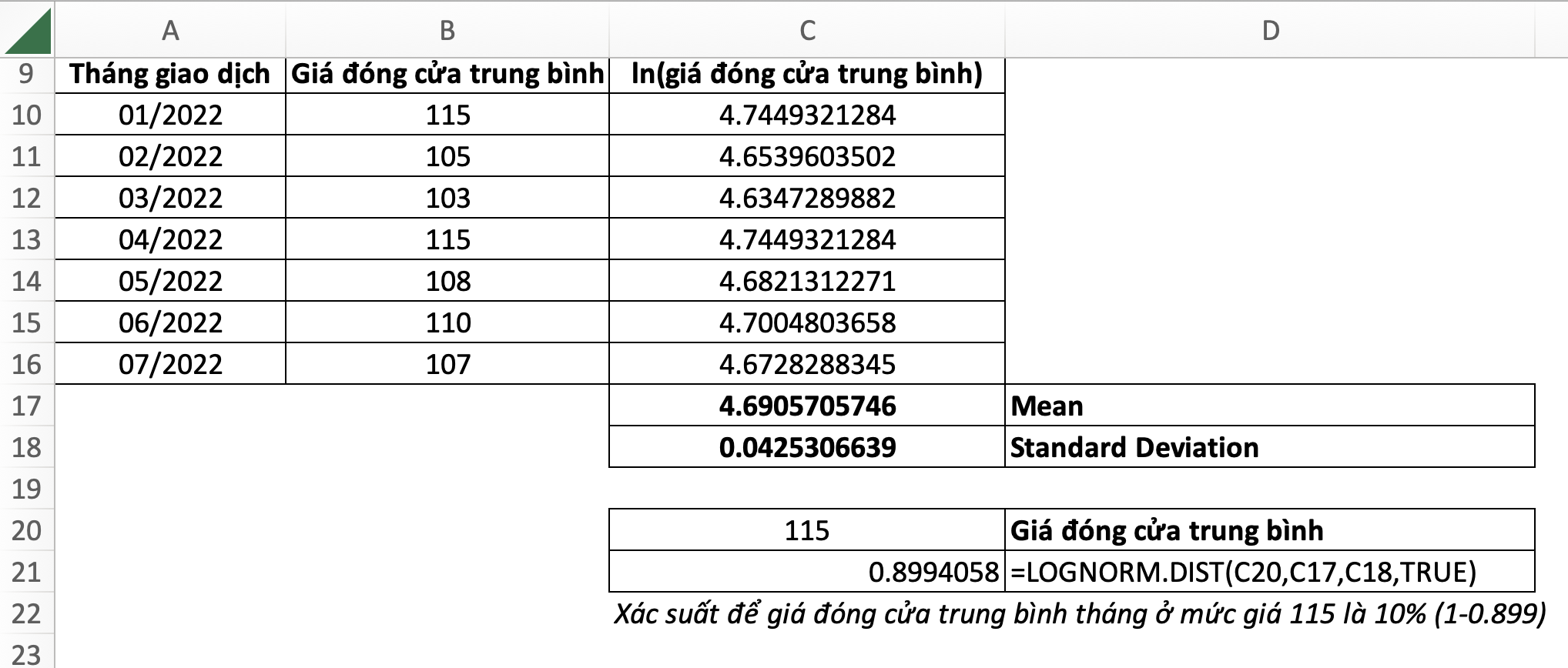
31. LOGNORM.DIST – Log-normal Distribution: Phân phối log-normal
=LOGNORM.DIST(x,mean,standard_dev,cumulative)- x: giá trị cần xác định phân phối
- mean: trung bình số học của phân phối
- standard_dev: độ lệch chuẩn của phân phối
- cumulative: TRUE (hoặc 1): hàm phân phối tích luỹ; FALSE (hoặc 0): hàm mật độ xác suất
Trong phân tích tài chính, hàm LOGNORM.DIST thường được dùng để phân tích giá cổ phiếu, trong khi phân phối chuẩn không thể dùng được trong mô hình giá chứng khoán vì phân phối chuẩn có chứa giá trị âm, nhưng thực tế thì chứng khoán không bao giờ có giá dưới 0.
Tìm hiểu thêm về cách sử dụng và ứng dụng của Lognormal Distribution tại đây.
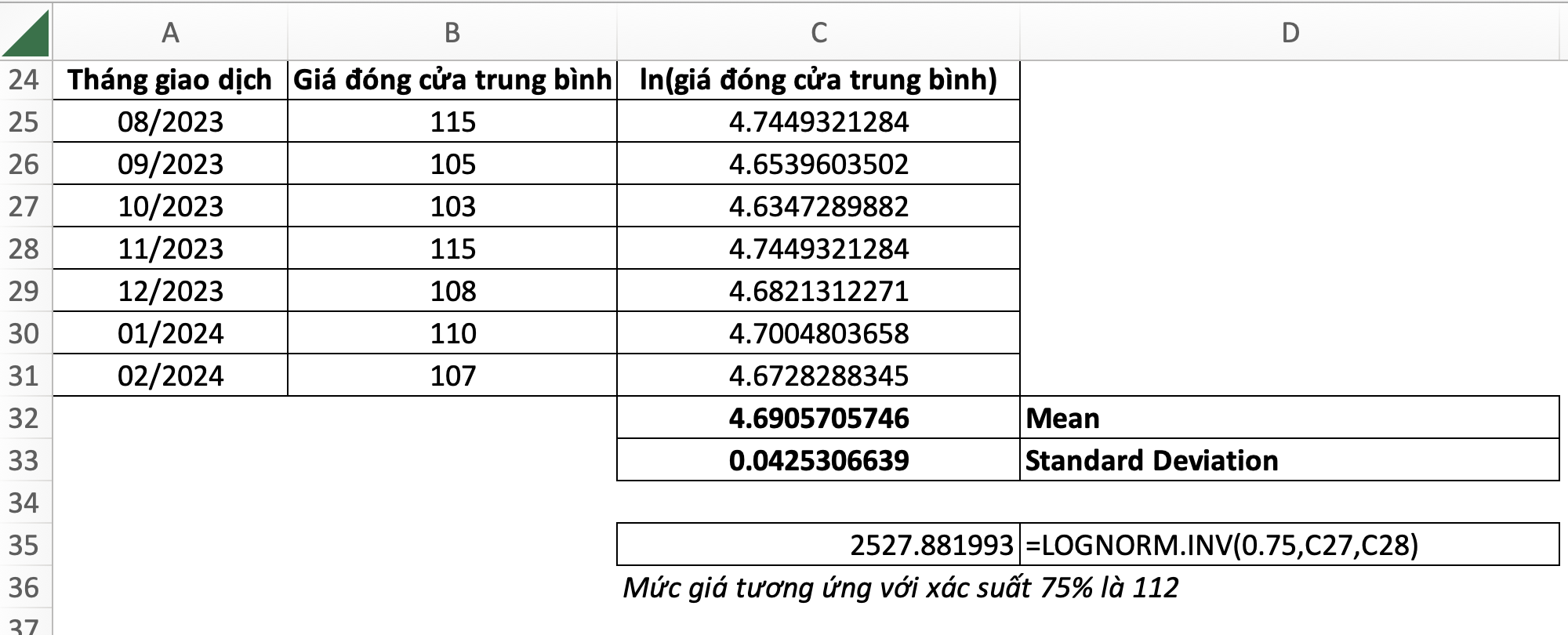
32. LOGNORM.INV – Log-normal Distribution Inverse – Nghịch đảo phân phối log-normal
=LOGNORM.INV(probability, mean, standard_dev)- probability: xác suất cho trước
- mean: trung bình số học của phân phối
- standard_dev: độ lệch chuẩn của phân phối
Student’s t-Distribution: Phân phối Student
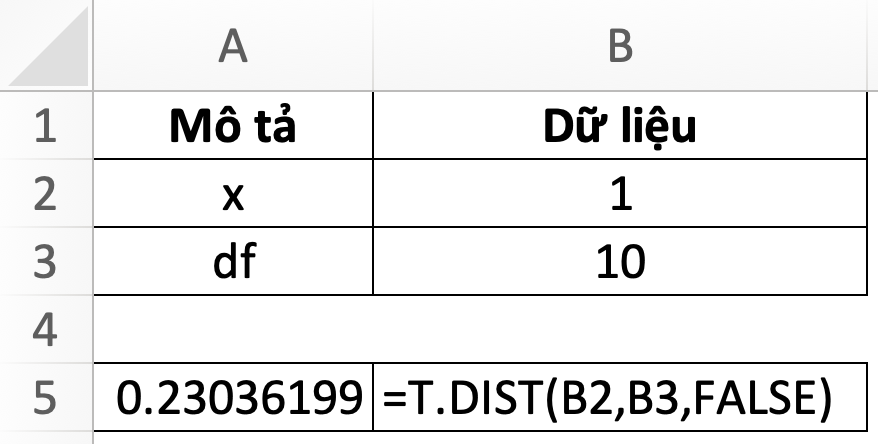
33. T.DIST – T Distribution – Phân phối t
=T.DIST(x,deg_freedom,cumulative)- x: giá trị muốn tính phân phối t
- deg_freedom: bậc tự do
- cumulative: TRUE (hoặc 1): hàm phân phối tích luỹ; FALSE (hoặc 0): hàm mật độ xác suất
T.DIST thường được dùng trong phân tích rủi ro danh mục đầu tư, mô hình hoá lợi nhuận thu được từ tài sản dựa vào “sức nặng” của các đuôi trong mô hình phân phối.
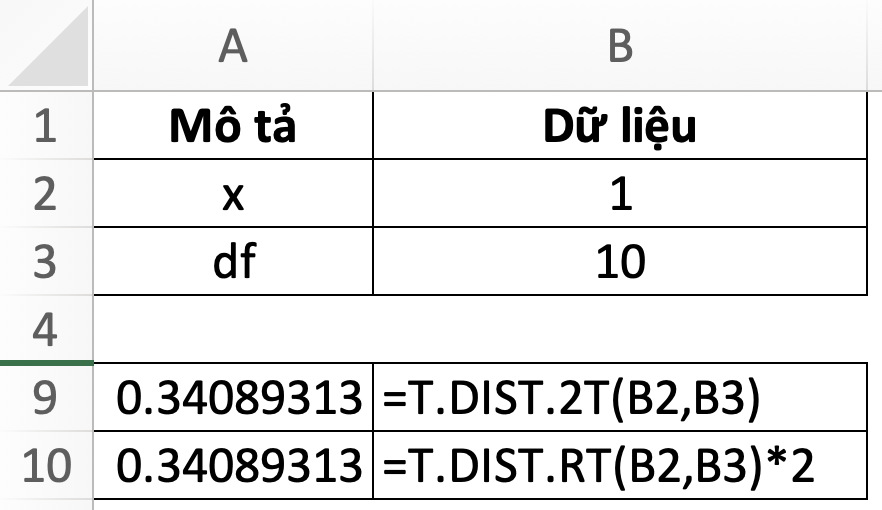
34. T.DIST.RT – Right-Tailed t-Distribution – Phân phối t đuôi phải
=T.DIST.RT(x,deg_freedom)- x: giá trị muốn tính phân phối t
- deg_freedom: bậc tự do

35. T.DIST.2T – 2-Tailed t-Distribution – Phân phối t hai đuôi
=T.DIST.2T(x,deg_freedom)- x: giá trị muốn tính phân phối t
- deg_freedom: bậc tự do
Poisson Distribution: Phân phối Poisson
36. POISSON.DIST – Poisson Distribution – Phân phối Poisson
=POISSON.DIST(x,mean,cumulative)- x: số các sự kiện muốn tìm phân bổ xác suất (lớn hơn hoặc bằng 0)
- mean: giá trị kỳ vọng thuộc kiểu dữ liệu số (lớn hơn hoặc bằng 0)
- cumulative: TRUE (hoặc 1): hàm phân phối tích luỹ; FALSE (hoặc 0): hàm mật độ xác suất

Hypergeometric Distribution: Phân phối Siêu bội
37. HYPGEOM.DIST – Hypergeometric Distribution – Phân phối Siêu bội
=HYPGEOM.DIST(x,n,k,m,cumulative)Từ một tập hợp gồm N phần tử (trong đó có M phần tử có tính chất A nào đó), lấy ngẫu nhiên không hoàn lại ra n phần tử . Gọi X là số phần tử có tính chất A có trong n phần tử lấy ra, thì X là đại lượng ngẫu nhiên rời rạc có thể nhận các giá trị trong khoảng [n1, n2], với các xác suất tương ứng:
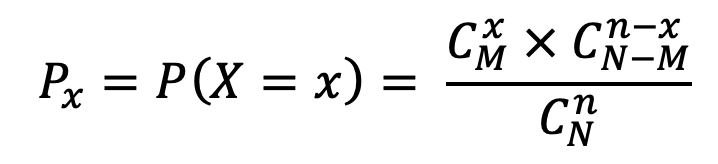
trong đó, x phải thoả mãn điều kiện: x ∈ [n1,n2]
n1=Max{0;M+n−N};
n2=Min{n;M}
Ví dụ: Một túi chứa 12 bóng, 8 rỏ 4 xanh. Lấy ngẫu nhiên 3 bóng từ 12 bóng (không hoàn lại). Xác suất lấy ra tối thiểu 2 bóng đều là màu xanh?
2 bóng xanh trong 3 bóng lấy ra: x=2,n=3,
12 bóng gồm 8 bóng đỏ và 4 bóng xanh: k=4,m=12

Chi Distribution: Phân phối Chi bình phương
38. CHISQ.TEST – Chi-Square Test – P-value của phân phối Chi-Square
=CHISQ.TEST(actual_range,expected_range)- actual-range: vùng giá trị thực tế
- expected_rage: vùng giá trị kỳ vọng
Ví dụ: Cho một bảng dữ liệu về quan hệ giữa Earning Growth và Dividend Yield. Với mức tin cậy 5%, liệu có thể kết luận Earning Growth và Dividend Yeild phụ thuộc nhau?
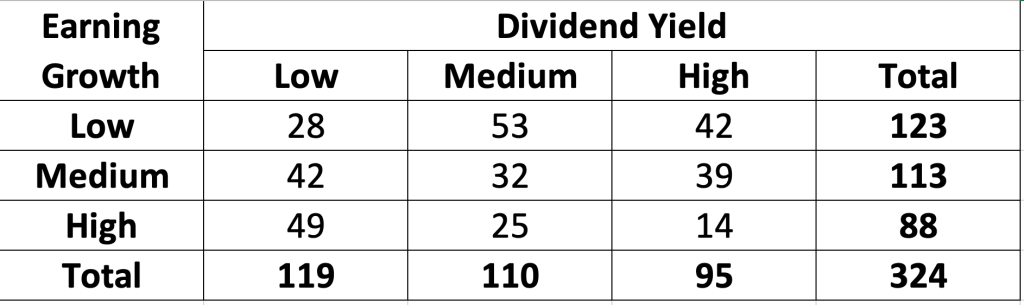
Bước 1: Chuyển bảng dữ liệu tương quan sang dạng Expected Frequencies theo công thức sau:
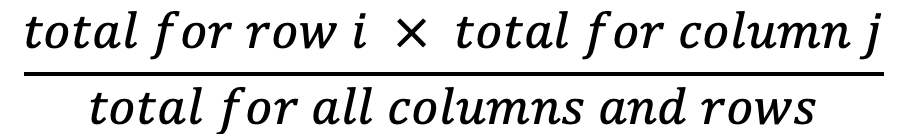
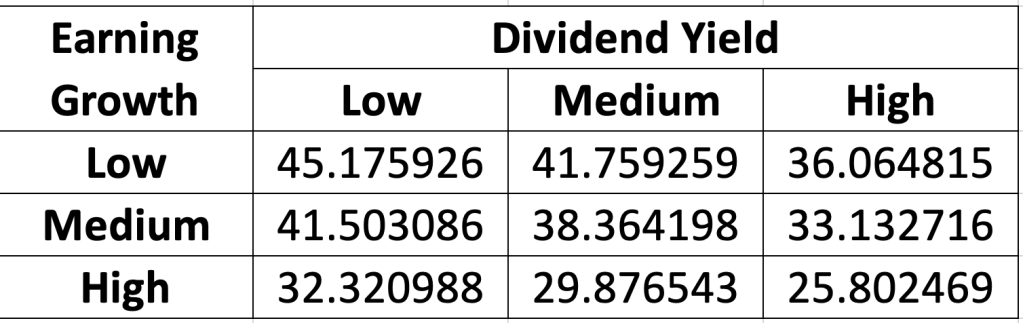
Bước 2: Tìm p-value của phân phối chi-square thông qua hàm CHISQ.TEST → bác bỏ giả thiết Earning Growth và Dividend Yeild phụ thuộc nhau, hay Earning Growth và Dividend Yeild độc lập với nhau.

Vì p-value = 0.00001625 < level of signifiance = 0.05
39. CHISQ.INV.RT – Inverse of Chi-Square Distribution – Nghịch đảo xác suất của phân phối Chi-Square
=CHISQ.INV.RT(probability,deg_freedom)- probability: xác suất
- degree of freedom: bậc tự do
Sử dụng ví dụ ở hàm 38, sử dụng công thức CHISQ.INV.RI để kết luận
Bước 1: Chuyển bảng dữ liệu tương quan sang dạng Expected Frequencies theo công thức sau:
Bước 2: Áp dụng công thức sau để tính chi-square test-statistic:
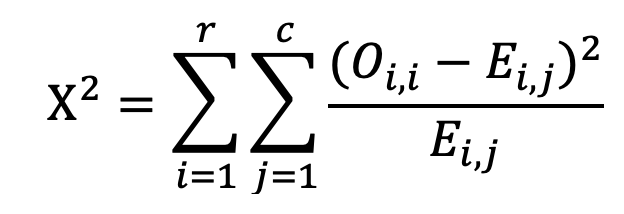
Ví dụ:
O₁,₁ = 28, E₁,₁ = 45.175926
O₁,₂ = 53, E₁,₂ = 41.759259
→ X² = 27.4352
Bước 3: Tính critical-value sử dụng CHISQ.INV.RT

Vì X² = 27.4352 > critical-value = 11.143287→ bác bỏ giả thiết Earning Growth và Dividend Yeild phụ thuộc nhau, hay Earning Growth và Dividend Yeild độc lập với nhau.
40. CHISQ.DIST – Chi-Square Distribution – Phân phối Chi-Square
=CHISQ.DIST(x,deg_freedom,cumulative)- x: giá trì muốn tính phân phối
- deg_freedom: bậc tự do
- cumulative: TRUE (hoặc 1): hàm phân phối tích luỹ; FALSE (hoặc 0): hàm mật độ xác suất
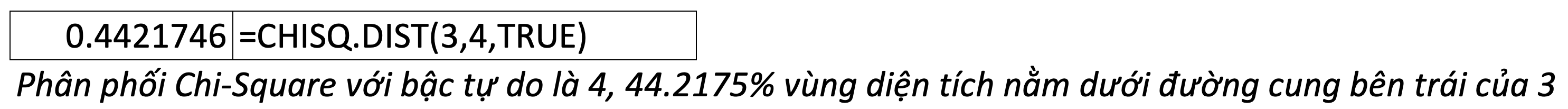
41. CHISQ.DIST.RT – Chi-Square Distribution Right-Tailed – Phân phối Chi-Square đuôi phải
=CHISQ.DIST.RT(x,deg_freedom)- x: giá trì muốn tính phân phối
- degree of freedom: bậc tự do
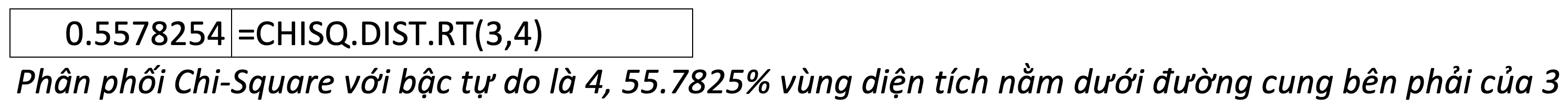
Hay có thể tính CHISQ.DIST.RT bằng cách:
CHISQ.DIST.RT = 1 - CHISQ.DIST(cummulative)42. CHISQ.INV – Inverse of Chi-Square Distribution – Nghịch đảo xác suất của phân phối Chi-Square
=CHISQ.INV(probability,deg_freedom)- probability: xác suất
- deg_freedom: bậc tự do

Hàm CHISQ.INV ngược với CHISQ.DIST.
Fisher-Snedecor Distribution: Phân phối F
43. F.TEST – Test-Statistic of F Distribution – Kiểm định thống kê của phân phối F
=F.TEST(array1,array2)- array1: mảng dữ liệu 1
- array2: mảng dữ liệu 2
Ví dụ: Cho dữ liệu thu thập được như hình bên dưới. Với mức ý nghĩa 5%, liệu có thể kết luận phương sai của Nữ bằng với phương sai của Nam không?
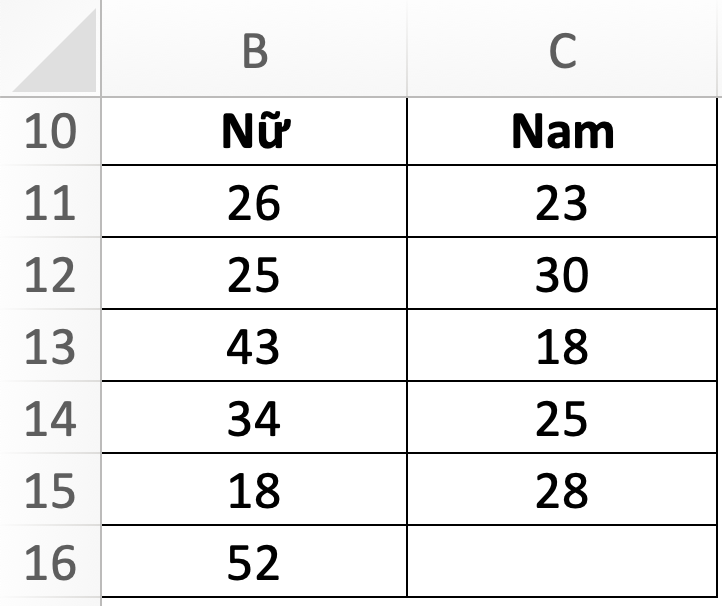
Tính test-statistic (2-tailed) bằng công thức F.TEST:

p-value = 0.0757 > level of significance = 0.05 (2-tailed)
hay
p-value = 0.0378 > level of significance/2 = 0.025 (1-tailed) → bác bỏ giả thiết phương sai của Nữ bằng với phương sai của Nam.
44. F.INV.RT – Inverse of F Distribution – Nghịch đảo xác suất của phân phối F
=F.INV.RT(probability,deg_freedom1,deg_freedom2)- probability: xác suất
- deg_freedom1: bậc tự do mẫu 1
- deg_freedom2: bậc tự do mẫu 2
Ví dụ: Cho số liệu về hai ngành công nghiệp sợi và giấy như bảng bên dưới. Liệu có thể kết luận độ lệch chuẩn của ngành sợi giống với ngành giấy không?

Bước 1: Tính test statistic bằng công thức:
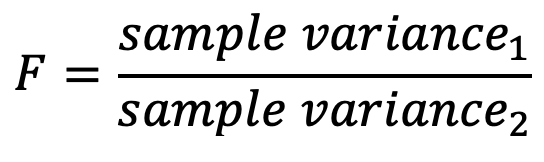
F = 4.3²/3.8² = 1.2805
Bước 2: Tính critical-value bằng công thức F.INV.RT

Vì F = 1.2805 < critical-value = 1.9429 → không thể bác bỏ giả thiết độ lệch chuẩn của ngành sợi giống với ngành giấy.
45. F.DIST – F Distribution – Phân phối F
=F.DIST(x,deg_freedom1,deg_freedom2,)- x: giá trì muốn tính phân phối
- deg_freedom1: bậc tự do mẫu 1
- deg_freedom2: bậc tự do mẫu 2
- cumulative: TRUE (hoặc 1): hàm phân phối tích luỹ; FALSE (hoặc 0): hàm mật độ xác suất
Hàm mật độ xác suất:

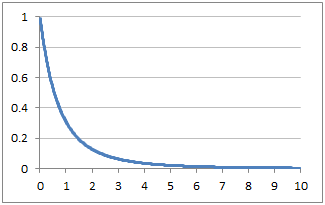
Nguồn ảnh: https://www.excelfunctions.net/excel-f-dist-function.html
Hàm phân phối tích luỹ:

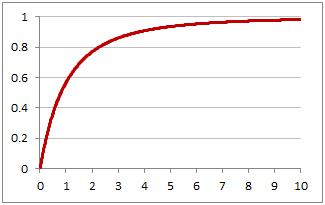
Nguồn ảnh: https://www.excelfunctions.net/excel-f-dist-function.html
46. F.DIST.RT – F Distribution Right-tailed – Phân phối F đuôi phải
=F.DIST.RT( x, deg_freedom1, deg_freedom2)- x: giá trì muốn tính phân phối
- deg_freedom1: bậc tự do mẫu 1
- deg_freedom2: bậc tự do mẫu 2